Method
The input motion sequence consisting of $t$ frames is first parameterized with Lie algebra parameters, i.e. instead of representing a motion frame in terms of raw 3D coordinates, we represent it with $\mathfrak{se}(3)$ kinematic chains of axis angles parameters relating the rotation of connected bones. The resultant pose sequence $\langle \mathrm{\mathbf{p}}_1, \cdots, \mathrm{\mathbf{p}}_t\rangle$ is then passed to a sequence-to-sequence model that encodes its motion context and a decoder then generate predictions for $\langle \mathrm{\mathbf{p}}_{t+1}, \cdots, \mathrm{\mathbf{p}}_{t+T}\rangle$.
In conventional motion prediction models, the encoder and decoder usually consist of single or stacked layers of LSTM or GRU cells. The inputs must be processed sequentially and the final hidden state tends to be dominated by the inputs at recent frames and cannot properly capture long-term dependencies. Consequently, predicted motion tends to converge to motionless states.
To effectively model motion dynamics, we propose a Hierarchical Motion Recurrent (HMR) network as the encoder, where the entire input sequence of poses is fed one-shot instead of successively. The motion contexts are modeled by
- $t-1$ frame-level hidden states, $\left\{\mathrm{\mathbf{h}}_{j}\right\}_{j=1}^{t-1}$ corresponding to the individual frames,
- $1$ sequence-level global state $\mathrm{\mathbf{g}}$ corresponding to the entire sequence.
$\mathrm{\mathbf{h}}_{j}$ and $\mathrm{\mathbf{g}}$ capture local and global motion contexts, respectively.
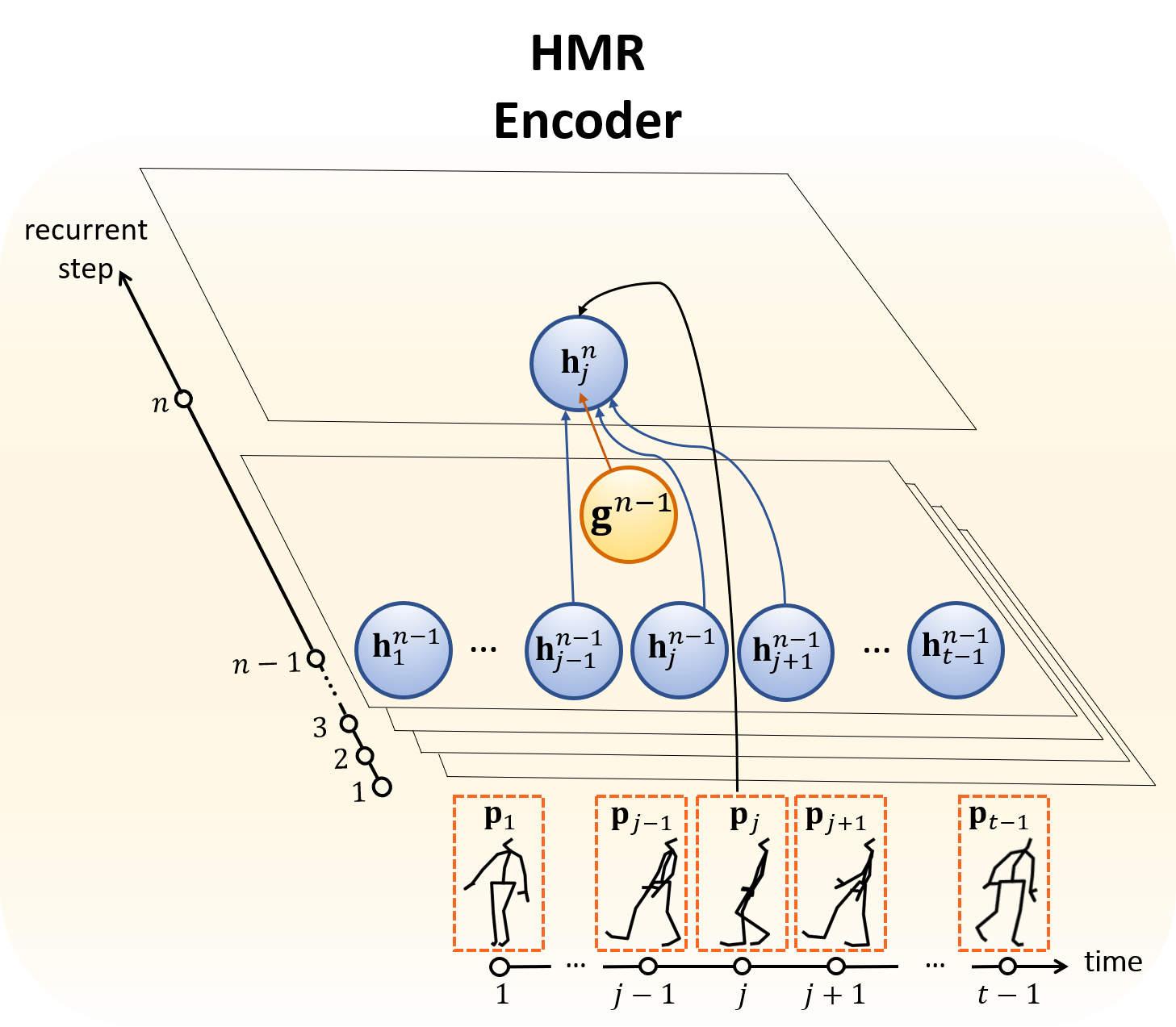
The detailed state transitions are as follows.

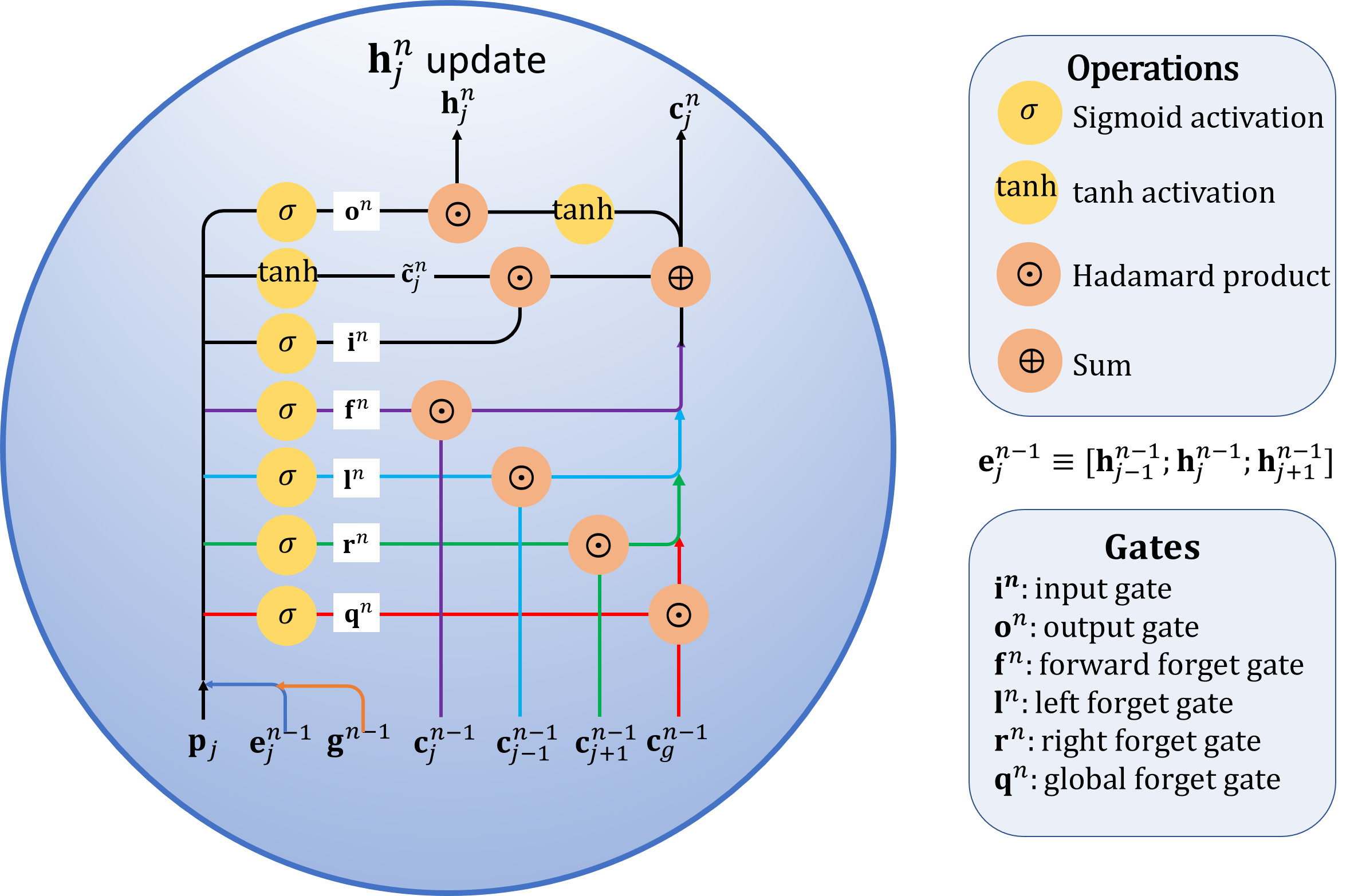
At each recurrent step $n$, $\mathrm{\mathbf{h}}_j^n$ is updated by exchanging information with its neighboring frames and with the global sequence-level state. There are a total of 4 types of forget gates: $\mathrm{\mathbf{f}}^n$, $\mathrm{\mathbf{l}}^n, \mathrm{\mathbf{r}}^n$, and $\mathrm{\mathbf{q}}^n$ (forward, left, right, and global forget gates), which respectively control the information flows from the current cell state $\mathrm{\mathbf{c}}_{j}^{n-1}$, left cell state $\mathrm{\mathbf{c}}_{j-1}^{n-1}$, right cell state $\mathrm{\mathbf{c}}_{j+1}^{n-1}$, and global cell state $\mathrm{\mathbf{c}}_g^{n-1}$ at recurrent step $n-1$ to the final cell state $\mathrm{\mathbf{c}}_j^n$ at recurrent step $n$. The input gate $\mathrm{\mathbf{i}}^n$ controls the information flow from the pose input $\mathrm{\mathbf{p}}_j$. Finally, the $j^{th}$ frame hidden state $\mathrm{\mathbf{h}}_j^n$ at recurrent step $n$ is updated by a Hadamard product of the

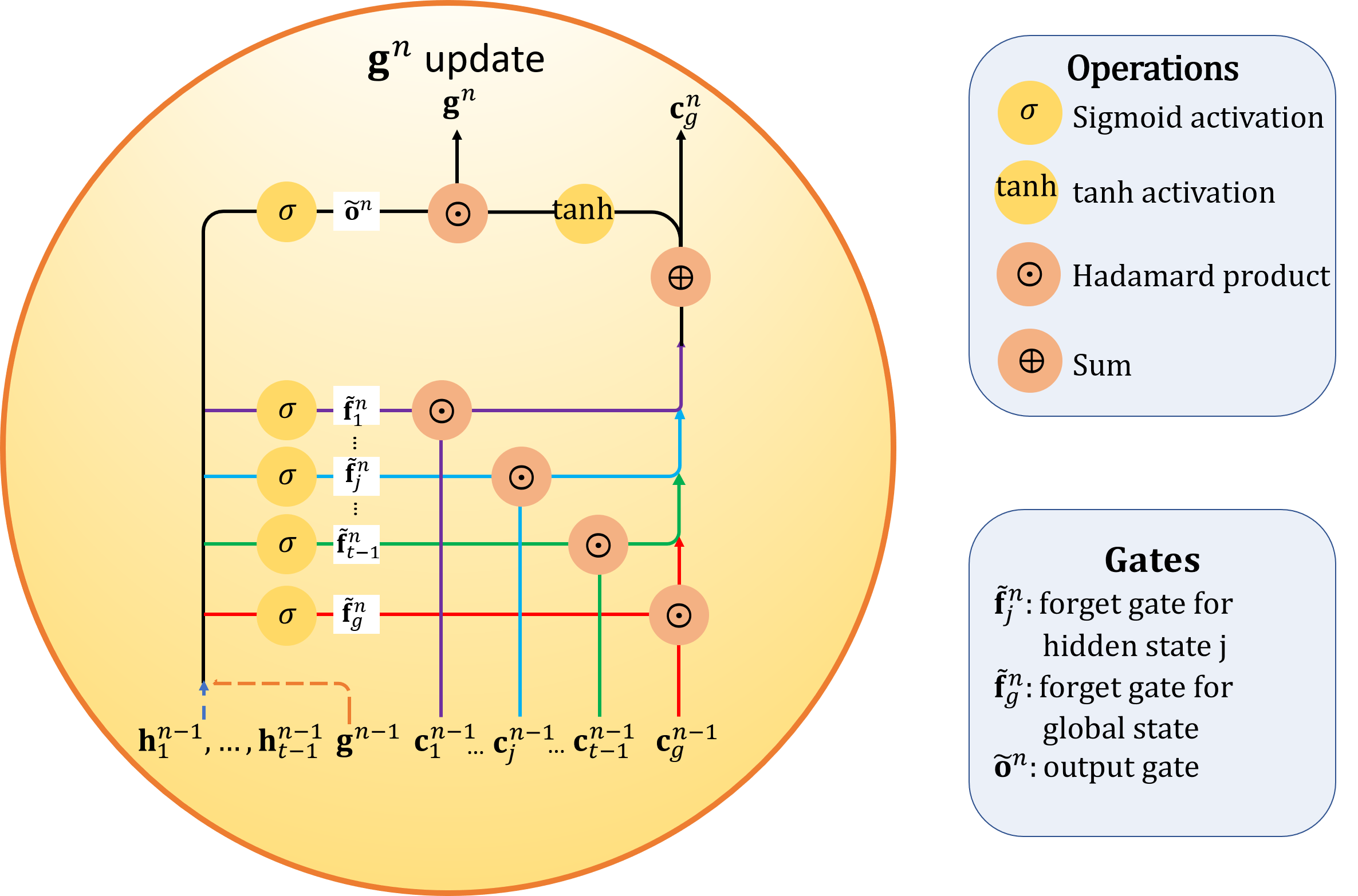
$\tilde{\mathrm{\mathbf{f}}}_g^n$ and $\tilde{\mathrm{\mathbf{f}}}_j^n$ are the respective forget gates that filter information from $\mathrm{\mathbf{c}}_g^{n-1}$ and $\mathrm{\mathbf{c}}_j^{n-1}$ to global cell state $\mathrm{\mathbf{c}}_g^n$. The global state $\tilde{\mathrm{\mathbf{g}}}^n$ at recurrent step $n$ is updated by a Hadamard product of the output gate $\tilde{\mathrm{\mathbf{o}}}_j^n$ with the $\tanh$ activated $\mathrm{\mathbf{c}}_g^n$.
The HMR encoder learns a two-level representation of the entire input sequence. It is subsequently passed to the decoder (a two-layer stacked LSTM network) that recursively outputs the future motion sequence. The pose $\mathrm{\mathbf{p}}_t$ serves as the initial input pose to the decoder. The decoder is executed following the directed links shown in the animated gif below to produce a pose prediction $\hat{\mathrm{\mathbf{p}}}_{t+1}$. It is then fed back as input to the subsequent cell of the decoder. Poses of subsequent frames are thus predicted in this recursive manner.

Publication
The code is uploaded in Github Github